I went for a regex that grouped smaller regexes by the pinyin's initial (usually the first letter). So, the first group includes all "b", "p" and "m" sounds, then "f", then "d" and "t", etc.
This approach seems easy to read and should be easy to edit (if it needs corrections or additions). I also added exceptions to the begging of groups in order to improve readability.
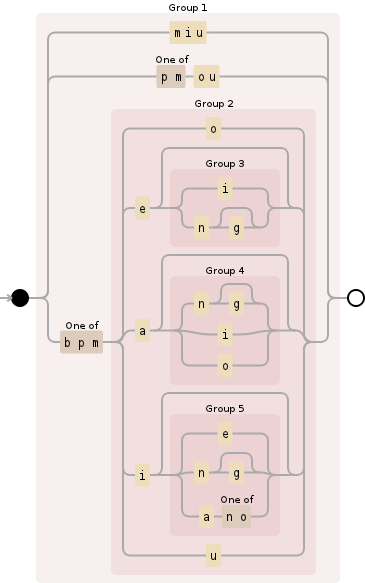
([mM]iu|[pmPM]ou|[bpmBPM](o|e(i|ng?)?|a(ng?|i|o)?|i(e|ng?|a[no])?|u))|
([fF](ou?|[ae](ng?|i)?|u))|([dD](e(i|ng?)|i(a[on]?|u))|
[dtDT](a(i|ng?|o)?|e(i|ng)?|i(a[on]?|e|ng|u)?|o(ng?|u)|u(o|i|an?|n)?))|
([nN]eng?|[lnLN](a(i|ng?|o)?|e(i|ng)?|i(ang|a[on]?|e|ng?|u)?|o(ng?|u)|u(o|i|an?|n)?|ve?))|
([ghkGHK](a(i|ng?|o)?|e(i|ng?)?|o(u|ng)|u(a(i|ng?)?|i|n|o)?))|
([zZ]h?ei|[czCZ]h?(e(ng?)?|o(ng?|u)?|ao|u?a(i|ng?)?|u?(o|i|n)?))|
([sS]ong|[sS]hua(i|ng?)?|[sS]hei|[sS][h]?(a(i|ng?|o)?|en?g?|ou|u(a?n|o|i)?|i))|
([rR]([ae]ng?|i|e|ao|ou|ong|u[oin]|ua?n?))|
([jqxJQX](i(a(o|ng?)?|[eu]|ong|ng?)?|u(e|a?n)?))|
(([aA](i|o|ng?)?|[oO]u?|[eE](i|ng?|r)?))|
([wW](a(i|ng?)?|o|e(i|ng?)?|u))|
[yY](a(o|ng?)?|e|in?g?|o(u|ng)?|u(e|a?n)?)
Here's the Debuggex example I created.
与恶龙缠斗过久,自身亦成为恶龙;凝视深渊过久,深渊将回以凝视…



